

Los modelos de lenguaje son algoritmos diseñados para procesar y generar texto de manera similar a como lo haría un humano. Su desarrollo ha sido clave en la evolución de la inteligencia artificial (IA), permitiendo aplicaciones como asistentes virtuales, generación de contenido, traducción automática y análisis de texto. En este artículo, exploraremos qué son, cómo funcionan, los diferentes tipos de modelos y sus principales aplicaciones.
¿Qué es un Modelo de Lenguaje?
Un modelo de lenguaje es un sistema basado en inteligencia artificial que predice la probabilidad de una secuencia de palabras en un texto. Se entrena con grandes volúmenes de datos para aprender patrones lingüísticos y generar respuestas coherentes en diferentes contextos.
Estos modelos pueden clasificarse según su tamaño y capacidades. Los más simples utilizan reglas estadísticas, mientras que los más avanzados emplean redes neuronales profundas, como las arquitecturas de Transformers, que han revolucionado la IA en los últimos años.
¿Cómo Funcionan los Modelos de Lenguaje?
El funcionamiento de un modelo de lenguaje se basa en el entrenamiento con grandes conjuntos de datos de texto. Durante este proceso, el modelo aprende la estructura del lenguaje, la semántica de las palabras y cómo se relacionan entre sí.
Proceso de Entrenamiento
- Recopilación de Datos: Se reúnen grandes volúmenes de texto de libros, artículos, páginas web y otros documentos.
- Preprocesamiento: Se limpian y organizan los datos, eliminando información irrelevante o sesgada.
- Tokenización: El texto se divide en unidades más pequeñas, llamadas tokens (palabras o fragmentos de palabras).
- Entrenamiento con Redes Neuronales: Se utiliza una arquitectura como Transformer para analizar la relación entre tokens y aprender patrones lingüísticos.
- Ajuste y Optimización: Se refina el modelo para mejorar su precisión y reducir errores.
Una vez entrenado, el modelo puede completar frases, responder preguntas, traducir idiomas y realizar otras tareas relacionadas con el procesamiento del lenguaje natural (NLP).
Modelos de Transformador
Los modelos de aprendizaje automático para el procesamiento de lenguaje natural han evolucionado a lo largo de muchos años. En la actualidad, los modelos de lenguaje grande más recientes se basan en la arquitectura del transformador, que aprovecha y amplía algunas técnicas que han demostrado su eficacia en el modelado de vocabularios para respaldar tareas de PLN y, en particular, en la generación de lenguaje. Los modelos de transformador se entrenan con grandes volúmenes de texto, lo que les permite representar las relaciones semánticas entre palabras y usar esas relaciones para determinar secuencias probables de texto que tienen sentido. Los modelos de transformador con un vocabulario lo suficientemente grande son capaces de generar respuestas de lenguaje difíciles de distinguir de las respuestas humanas.
Arquitectura de los Modelos de Transformador
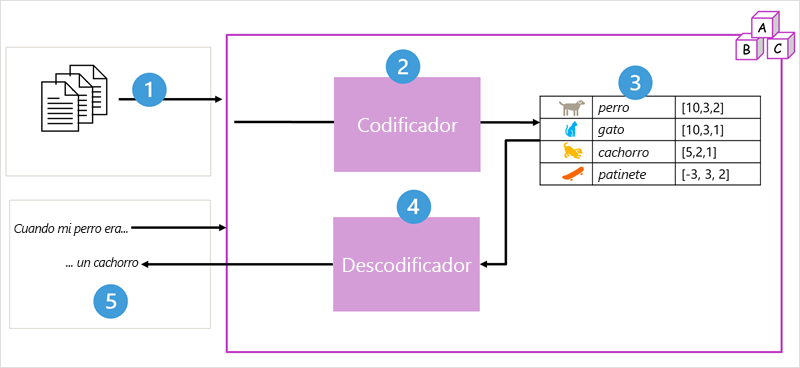
La arquitectura del modelo de transformador consta de dos componentes o bloques:
- Bloque codificador que crea representaciones semánticas del vocabulario de entrenamiento.
- Bloque descodificador que genera nuevas secuencias de lenguaje.
El modelo se entrena con un gran volumen de texto de lenguaje natural, a menudo procedente de Internet u otros orígenes públicos de texto.
- Las secuencias de texto se dividen en tokens (por ejemplo, palabras individuales) y el bloque del codificador procesa estas secuencias de tokens mediante una técnica denominada atención para determinar las relaciones entre tokens.
- La salida del codificador es una colección de vectores (matrices numéricas con varios valores) en la que cada elemento del vector representa un atributo semántico de los tokens. Estos vectores se conocen como incrustaciones.
- El bloque de descodificador funciona con una nueva secuencia de tokens de texto y usa las incrustaciones generadas por el codificador para generar una salida de lenguaje natural adecuada.
- Por ejemplo, dada una secuencia de entrada como "Cuando mi perro era", el modelo puede usar la técnica de atención para analizar los tokens de entrada y los atributos semánticos codificados en las incrustaciones para predecir una finalización adecuada de la frase, como "un cachorro".
En la práctica, las implementaciones específicas de la arquitectura varían, por ejemplo:
- BERT (Bidirectional Encoder Representations from Transformers) desarrollado por Google usa solo el bloque codificador.
- GPT (Generative Pre-trained Transformer) desarrollado por OpenAI usa solo el bloque descodificador.
Tokenización
El primer paso para entrenar un modelo de transformador es descomponer el texto de entrenamiento en tokens, es decir, identificar cada valor de texto único.
Por ejemplo, considere la siguiente oración:
I heard a dog bark loudly at a cat
Para tokenizar este texto, puede identificar cada palabra discreta y asignarle identificadores de token:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- ("a" ya está tokenizado como 3)
- cat (8)
La oración ahora se puede representar con los tokens: {1 2 3 4 5 6 7 3 8}.
Incrustaciones (Embeddings)
Los tokens se convierten en vectores contextuales, llamados incrustaciones. Estos vectores representan el significado y relaciones semánticas entre palabras.
Ejemplo de vectores:
- dog (perro): [10,3,2]
- cat (gato): [10,3,1]
- puppy (cachorro): [5,2,1]
- skateboard (monopatín): [-3,3,2]
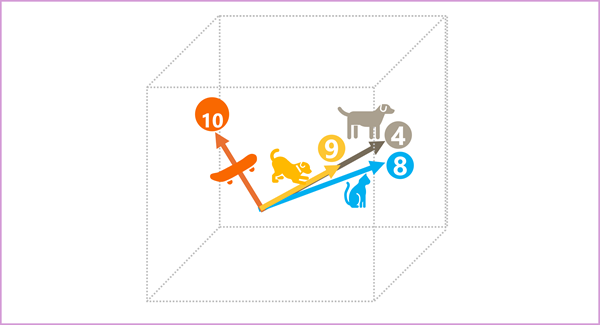
Los vectores de "perro" y "cachorro" tienen direcciones similares en un espacio multidimensional, lo que indica que tienen significados relacionados.
Atención
Los bloques codificador y descodificador incluyen varias capas de redes neuronales, entre ellas las capas de atención. La autoatención evalúa la relación entre los tokens en una oración.
Ejemplo:
"I heard a dog" → La capa de atención puede asignar más peso a "heard" y "dog" para predecir el siguiente token "bark".
El proceso de atención se optimiza mediante técnicas como la atención multicabezal, lo que permite al modelo evaluar varias relaciones entre tokens simultáneamente.
Aplicaciones de los Modelos de Transformador
Los modelos de transformador han revolucionado múltiples áreas, entre ellas:
- Motores de búsqueda: BERT se utiliza en Google Search para entender mejor las consultas de los usuarios.
- Generación de texto: GPT se emplea para chatbots y creación automática de contenido.
- Traducción automática: Modelos como T5 (Text-To-Text Transfer Transformer) mejoran la traducción de idiomas.
- Resumen automático de textos: Los transformadores permiten condensar información manteniendo la coherencia y el significado.
Los avances en los modelos de transformador continúan, con arquitecturas cada vez más eficientes y capaces de realizar tareas complejas en el ámbito del procesamiento del lenguaje natural.

Tipos de Modelos de Lenguaje
Existen diferentes modelos de lenguaje según su tamaño y aplicación. Podemos clasificarlos en:
Modelos de Lenguaje Pequeños
Son modelos livianos que requieren menos recursos computacionales y están optimizados para tareas específicas. Algunos ejemplos incluyen:
- BERT Pequeño: Optimizado para análisis de sentimientos y clasificación de texto.
- GPT-2 Pequeño: Versión reducida del modelo GPT para generación de texto en dispositivos con menos capacidad.
- T5 Pequeño: Utilizado para tareas de resumen y transformación de texto.
Estos modelos son ideales para aplicaciones locales, asistentes personales y dispositivos con hardware limitado.
Modelos de Lenguaje Grandes (LLM, Large Language Models)
Son modelos avanzados con miles de millones de parámetros, capaces de generar textos complejos y entender el contexto de manera profunda. Ejemplos incluyen:
- GPT-4: Utilizado en asistentes conversacionales avanzados y generación de contenido.
- PaLM 2: Modelo de Google diseñado para tareas de razonamiento y traducción avanzada.
- LLaMA: Desarrollado por Meta, optimizado para IA generativa en múltiples aplicaciones.
Estos modelos requieren gran capacidad de procesamiento y suelen ser implementados en la nube para ofrecer respuestas en tiempo real.
Aplicaciones de los Modelos de Lenguaje
Los modelos de lenguaje se utilizan en diversos sectores para automatizar tareas y mejorar la interacción con los usuarios. Algunas de sus aplicaciones más comunes son:
1. Asistentes Virtuales y Chatbots
Plataformas como ChatGPT, Google Assistant y Siri utilizan modelos de lenguaje para responder preguntas, dar recomendaciones y asistir en diversas tareas.
2. Generación de Contenido
Los modelos de IA pueden redactar artículos, crear publicaciones para redes sociales y generar contenido creativo en múltiples formatos.
3. Traducción Automática
Herramientas como Google Translate y DeepL emplean modelos avanzados para traducir textos con precisión en diferentes idiomas.
4. Análisis de Sentimientos
Empresas utilizan modelos de lenguaje para analizar opiniones en redes sociales, encuestas y comentarios de clientes, mejorando la toma de decisiones.
5. Programación Asistida
Herramientas como GitHub Copilot ayudan a los desarrolladores a escribir código más rápido y con menos errores.
6. Medicina y Ciencias
En el sector salud, los modelos de lenguaje se aplican en la revisión de documentos médicos, diagnóstico asistido y descubrimiento de fármacos.
Futuro de los Modelos de Lenguaje
El desarrollo de modelos de lenguaje sigue avanzando con enfoques más eficientes y sostenibles. Algunas tendencias clave incluyen:
- Modelos más eficientes: Reducción del consumo energético sin perder capacidad de respuesta.
- Especialización: Modelos diseñados para áreas específicas, como derecho, salud o educación.
- Integración multimodal: Combinación de texto, imágenes y audio en un solo modelo.
En conclusión, los modelos de lenguaje han transformado la manera en que interactuamos con la tecnología, facilitando la automatización de tareas y mejorando la experiencia del usuario en múltiples sectores. Su evolución promete seguir revolucionando la inteligencia artificial en los próximos años.