

Introducción
Los datos relacionales son el pilar fundamental de muchas aplicaciones empresariales y bases de datos modernas. En este post, exploraremos los conceptos esenciales de los datos relacionales en Azure, su normalización, el lenguaje SQL y los diferentes tipos de instrucciones SQL que se utilizan para gestionar bases de datos en la nube.
¿Qué son los Datos Relacionales?
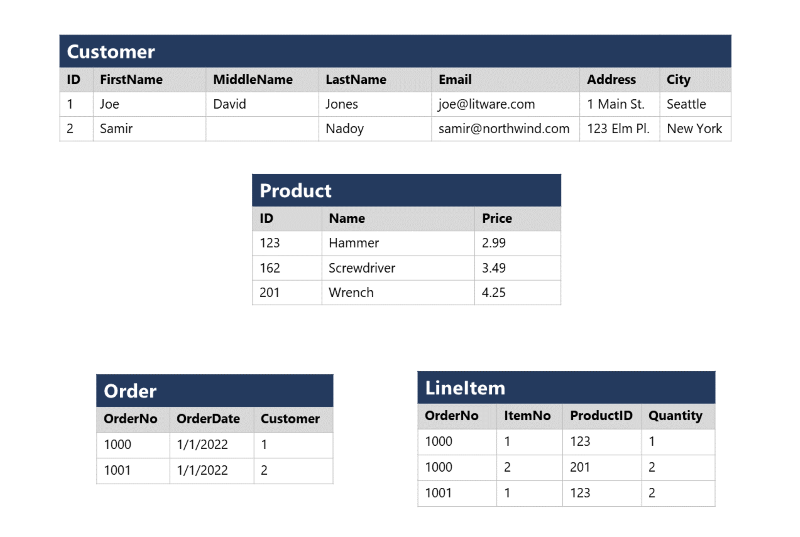
Los datos relacionales se organizan en tablas, donde cada fila representa una entidad y cada columna define un atributo específico. Esto permite estructurar la información de manera eficiente y reducir la redundancia de datos.
Ejemplo:
Características Claves de los Datos Relacionales
- Estructura tabular: Datos organizados en filas y columnas.
- Relaciones entre entidades: A través de claves primarias y claves foráneas.
- Integridad referencial: Garantiza que los datos sean coherentes y exactos.
- Consultas estructuradas: Se utilizan lenguajes como SQL para acceder y manipular la información.
Normalización de Datos
La normalización es el proceso de diseño de bases de datos que minimiza la redundancia y mejora la integridad de los datos. Se logra dividiendo los datos en múltiples tablas relacionadas mediante la aplicación de diferentes formas normales.
Formas Normales
- Primera Forma Normal (1NF): Se asegura que cada celda contenga un solo valor y que todas las columnas tengan valores atómicos.
- Segunda Forma Normal (2NF): Se eliminan dependencias parciales, asegurando que cada columna dependa completamente de la clave primaria.
- Tercera Forma Normal (3NF): Se eliminan dependencias transitivas, garantizando que los atributos no clave dependan directamente de la clave primaria.
- Forma Normal de Boyce-Codd (BCNF): Una versión más estricta de la 3NF que elimina dependencias funcionales redundantes.
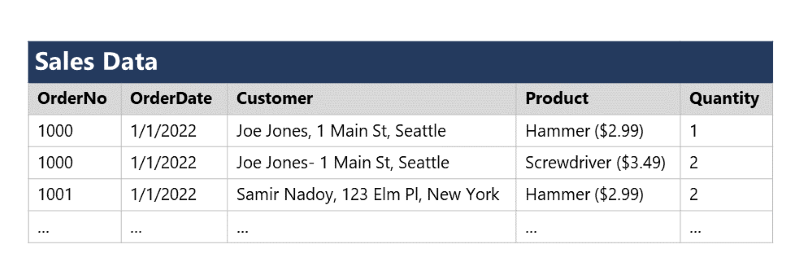
Ejemplo de normalización:

La normalización mejora la eficiencia de las consultas y facilita la escalabilidad, pero en ciertos casos, puede ser necesario desnormalizar la base de datos para optimizar el rendimiento en sistemas de lectura intensiva.
Exploración de SQL
SQL (Structured Query Language) es el lenguaje estándar para interactuar con bases de datos relacionales. Se divide en diferentes tipos de instrucciones:
Lenguaje de Definición de Datos (DDL)
Estas instrucciones se utilizan para definir y modificar la estructura de una base de datos.
Ejemplo:
CREATE TABLE Productos (
ID INT PRIMARY KEY,
Nombre VARCHAR(50) NOT NULL,
Precio DECIMAL(10,2) NOT NULL
);Lenguaje de Manipulación de Datos (DML)
Estas instrucciones se usan para insertar, actualizar y eliminar datos.
Ejemplo:
INSERT INTO Productos (ID, Nombre, Precio) VALUES (1, 'Laptop', 800.00);
UPDATE Productos SET Precio = 750.00 WHERE ID = 1;
DELETE FROM Productos WHERE ID = 1;Lenguaje de Control de Datos (DCL)
Se usa para gestionar permisos de acceso a los datos.
Ejemplo:
GRANT SELECT, INSERT ON Productos TO usuario1;
REVOKE INSERT ON Productos FROM usuario1;Lenguaje de Control de Transacciones (TCL)
Se usa para gestionar transacciones y asegurar la integridad de los datos.
Ejemplo:
BEGIN TRANSACTION;
UPDATE Productos SET Precio = 700 WHERE ID = 1;
COMMIT;Beneficios de Usar Bases de Datos Relacionales en Azure
Microsoft Azure ofrece diversas soluciones para gestionar bases de datos relacionales, como:
- Azure SQL Database: Un servicio de base de datos completamente administrado.
- Azure Database for MySQL y PostgreSQL: Opciones para bases de datos de código abierto.
- Azure Synapse Analytics: Solución de almacenamiento y procesamiento de grandes volúmenes de datos.
Descripción de objetos de base de datos
Además de las tablas, una base de datos relacional puede contener otras estructuras que ayudan a optimizar la organización de los datos, encapsular acciones mediante programación y mejorar la velocidad de acceso. En esta unidad, obtendrá información acerca de tres de estas estructuras con más detalle: vistas, procedimientos almacenados e índices.
¿Qué es una vista?
Una vista es una tabla virtual basada en los resultados de una consulta SELECT. Podría decirse que una vista es como una ventana que muestra unas filas concretas de una o varias tablas subyacentes. Por ejemplo, podría crear una vista en las tablas Order y Customer que recupere los datos de pedidos y clientes para proporcionar un objeto único que haga más fácil determinar las direcciones de entrega de los pedidos:
CREATE VIEW Deliveries
AS
SELECT o.OrderNo, o.OrderDate,
c.FirstName, c.LastName, c.Address, c.City
FROM Order AS o JOIN Customer AS c
ON o.Customer = c.ID;Puede consultar la vista y filtrar los datos de la misma forma que una tabla. La consulta siguiente busca detalles de los pedidos de los clientes que viven en Seattle:
SELECT OrderNo, OrderDate, LastName, Address
FROM Deliveries
WHERE City = 'Seattle';¿Qué es un procedimiento almacenado?
Un procedimiento almacenado define instrucciones SQL que se pueden ejecutar a petición. Los procedimientos almacenados se usan para encapsular la lógica de programación en una base de datos para las acciones que las aplicaciones deben realizar al trabajar con datos.
Puede definir un procedimiento almacenado con parámetros a fin de crear una solución flexible para las acciones comunes que podrían tener que aplicarse a los datos en función de una clave o criterios específicos. Por ejemplo, se podría definir el siguiente procedimiento almacenado para cambiar el nombre de un producto en función del identificador de producto especificado.
CREATE PROCEDURE RenameProduct
@ProductID INT,
@NewName VARCHAR(20)
AS
UPDATE Product
SET Name = @NewName
WHERE ID = @ProductID;Cuando haya que cambiar el nombre de un producto, puede ejecutar el procedimiento almacenado y pasar el identificador del producto y el nuevo nombre que se va a asignar:
EXEC RenameProduct 201, 'Spanner';¿Qué es un índice?
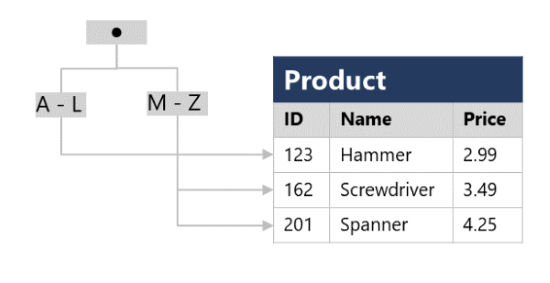
Un índice le ayuda a buscar datos en una tabla. Piense en el índice de una tabla como en el índice de la parte final de un libro. El índice de un libro contiene un conjunto ordenado de contenido, junto a las páginas en las que aparece. El índice le servirá para buscar la referencia a un elemento del libro. Puede usar los números de página del índice para ir directamente a las páginas correctas del libro. Sin el índice, es posible que tenga que leer todo el libro para encontrar el contenido que está buscando.
Cuando se crea un índice en una base de datos, se especifica una columna de la tabla; el índice contiene una copia de estos datos con un criterio de ordenación y punteros a las filas correspondientes de la tabla. Cuando el usuario ejecuta una consulta que especifica esa columna en la cláusula WHERE, el sistema de administración de bases de datos puede utilizar el índice para capturar los datos más rápidamente que si tuviera que examinar toda la tabla fila por fila.
Por ejemplo, podría usar el código siguiente para crear un índice en la columna Name de la tabla Product:
CREATE INDEX idx_ProductName
ON Product(Name);El índice crea una estructura basada en árbol que el optimizador de consultas del sistema de base de datos puede usar para buscar rápidamente filas en la tabla Product en función de un nombre específico (Name).
Beneficios de Usar Bases de Datos Relacionales en Azure
Microsoft Azure ofrece diversas soluciones para gestionar bases de datos relacionales, como:
- Azure SQL Database: Un servicio de base de datos completamente administrado.
- Azure Database for MySQL y PostgreSQL: Opciones para bases de datos de código abierto.
- Azure Synapse Analytics: Solución de almacenamiento y procesamiento de grandes volúmenes de datos.
Conclusión
El uso de bases de datos relacionales en Azure permite optimizar el almacenamiento, gestión y seguridad de los datos empresariales. Comprender la normalización, los tipos de instrucciones SQL y las herramientas disponibles en Azure es clave para desarrollar aplicaciones escalables y eficientes.