

Introducción
El servicio Visión de Azure AI proporciona una solución integral para implementar funcionalidades de visión por computadora sin necesidad de desarrollar modelos desde cero. Aunque es posible entrenar modelos personalizados usando herramientas como Azure Machine Learning, este enfoque puede ser complejo, ya que requiere grandes volúmenes de datos, tiempo de entrenamiento y recursos computacionales avanzados.
Microsoft facilita este proceso con Visión de Azure AI, que ofrece modelos precompilados y opciones de personalización. Estos modelos están basados en Florence, un modelo de base altamente eficaz que permite implementar soluciones de visión artificial con rapidez, precisión y flexibilidad.
Computer Vision, o Visión por Computadora, es un campo apasionante de la inteligencia artificial que permite a las máquinas "ver" e interpretar el mundo visual como lo hacen los humanos. A través del análisis de imágenes y videos, las aplicaciones de Computer Vision pueden identificar objetos, reconocer patrones y tomar decisiones basadas en lo que “observan”.
Las computadoras no tienen ojos como los humanos, pero pueden analizar datos visuales en forma de matrices de píxeles. Cada imagen digital se convierte en una estructura numérica que las máquinas procesan usando filtros y modelos matemáticos avanzados.
Gracias a técnicas como los filtros convolucionales y redes neuronales convolucionales (CNN), las máquinas pueden extraer características relevantes de imágenes y aprender a clasificarlas o reconocer elementos dentro de ellas. Esto abre un sinfín de posibilidades en áreas como seguridad, salud, automatización industrial, comercio minorista y más.
¿Qué es una imagen digital para una computadora?
Cuando nosotros vemos una imagen, percibimos formas, colores y emociones. Pero para una computadora, una imagen es una matriz de números.
¿Qué es un píxel?

- Un píxel (picture element) es la unidad mínima de una imagen digital.
- Cada píxel contiene información de intensidad (en blanco y negro) o de color (en imágenes RGB).
Ejemplo de una imagen en escala de grises de 3x3:
cssCopiarEditar[ 0, 80, 255 ]
[ 50, 128, 200 ]
[ 90, 170, 30 ]
Cada número representa qué tan claro u oscuro es ese píxel. 0 es negro, 255 es blanco.
¿Y el color?

Las imágenes a color usan el sistema RGB (Red, Green, Blue). Cada canal es una matriz del mismo tamaño, y los tres canales combinados forman la imagen final.
Ejemplo:
Una imagen de 100x100 píxeles a color tiene 3 matrices de 100x100 = 30,000 datos numéricos.
2. Procesamiento de imágenes: Uso de filtro
El procesamiento de imágenes consiste en aplicar transformaciones para mejorar, modificar o analizar las imágenes. Esto se hace usando filtros o kernels.
¿Qué es un filtro?
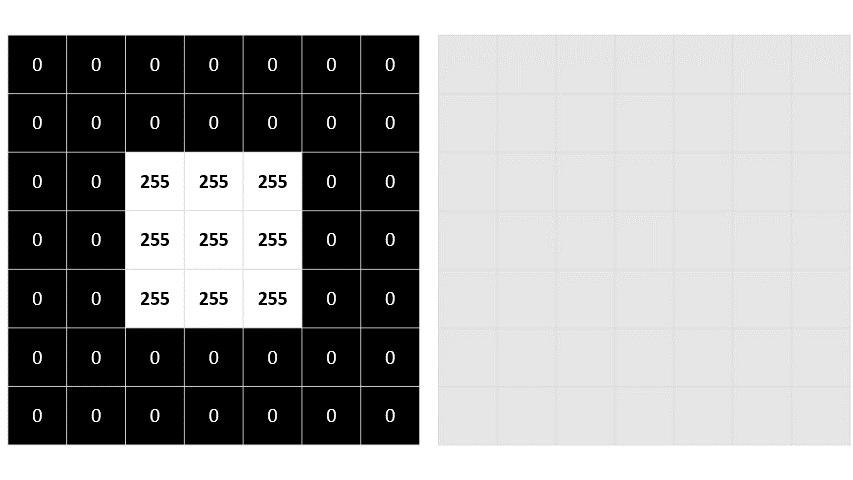
Un filtro es una pequeña matriz (por ejemplo, de 3x3 o 5x5) que se desplaza por toda la imagen (operación conocida como convolución) para alterar los valores de los píxeles de acuerdo a un patrón específico.
Ejemplo: Filtro Laplaciano para detección de bordes:
diffCopiarEditar-1 -1 -1
-1 8 -1
-1 -1 -1
Este filtro resalta cambios bruscos en la intensidad, es decir, bordes o contornos en una imagen.
¿Qué tipo de filtros existen?
- Desenfoque (Blur): suaviza la imagen.
- Nitidez (Sharpen): resalta detalles.
- Detección de bordes (Edge Detection): encuentra límites entre objetos.
- Emboss, Sobel, Gaussian Blur: otros filtros especializados.
¿Por qué son importantes?
Los filtros permiten a los sistemas extraer características clave de las imágenes que luego usarán para tareas más complejas como clasificación o segmentación.
3. Aprendizaje automático en visión por computadora
El procesamiento tradicional tiene límites. Para tareas complejas como reconocer rostros, automóviles o señales de tránsito, se requiere aprendizaje automático (machine learning).
| Imagen original | Imagen filtrada |
|---|---|
 | 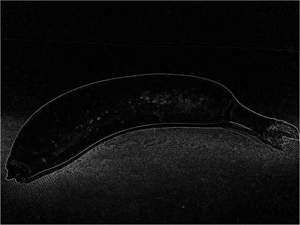 |
¿Cómo aprenden las máquinas?
A través de entrenamiento supervisado. Se le muestran miles o millones de imágenes etiquetadas (por ejemplo: esta imagen es un perro, esta es un gato), y el modelo aprende patrones que las distinguen.
Con el tiempo, el modelo generaliza y puede identificar nuevas imágenes con gran precisión.
4. Redes Neuronales Convolucionales (CNNs)
Las Convolutional Neural Networks (CNNs) son un tipo especial de red neuronal diseñada para trabajar con imágenes.
Estructura básica de una CNN
- Capas convolucionales: aplican filtros automáticamente para detectar patrones visuales (líneas, formas, colores).
- Capas de activación (ReLU): introducen no linealidad, lo cual ayuda al aprendizaje.
- Capas de pooling: reducen el tamaño de los datos para hacer el modelo más eficiente.
- Capas densas (fully connected): conectan todos los datos procesados y permiten tomar decisiones (clasificación).
¿Qué hacen las CNN?
- Identifican patrones en niveles:
- Capas iniciales → bordes y colores
- Capas intermedias → formas o texturas
- Capas finales → rostros, autos, animales
Ejemplo práctico
Entrenamiento para reconocer frutas:
- Se alimenta la red con miles de imágenes etiquetadas de manzanas, naranjas y plátanos.
- La red ajusta automáticamente sus filtros para aprender diferencias de forma, textura y color.
- Al final, puedes subir una imagen nueva y la CNN predecirá de qué fruta se trata.
Transformadores
La mayoría de los avances en Computer Vision durante las décadas han sido impulsados por mejoras en los modelos basados en CNN. Sin embargo, en otra materia de inteligencia artificial: procesamiento de lenguaje natural (NLP), otro tipo de arquitectura de red neuronal, denominada transformador ha habilitado el desarrollo de modelos sofisticados para el lenguaje. Los transformadores funcionan mediante el procesamiento de grandes volúmenes de datos y el lenguaje de codificación tokens (que representan palabras o frases individuales) como incrustaciones de vectores (matrices de valores numéricos). Puede pensar en una inserción como una representación de un conjunto de dimensiones que cada una representa algún atributo semántico del token. Las incrustaciones se crean de forma que los tokens que se usan normalmente en el mismo contexto definen vectores que están más alineados que las palabras no relacionadas.
Como ejemplo sencillo, en el diagrama siguiente se muestran algunas palabras codificadas como vectores tridimensionales y trazadas en un espacio 3D:

Los tokens que son semánticamente similares se codifican en direcciones similares, creando un modelo de lenguaje semántico que permite crear soluciones sofisticadas de NLP para el análisis de texto, la traducción, la generación de lenguajes y otras tareas.
Modelos multi modales
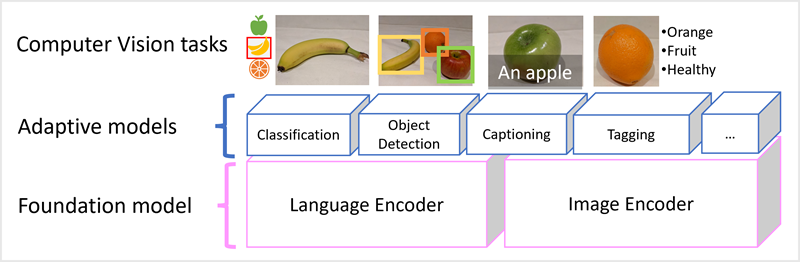
El éxito de los transformadores como una manera de crear modelos de lenguaje ha llevado a los investigadores de inteligencia artificial a considerar si el mismo enfoque sería eficaz para los datos de imagen. El resultado es el desarrollo de modelos de multi modales, en los que el modelo se entrena mediante un gran volumen de imágenes con subtítulos, sin etiquetas fijas. Un codificador de imágenes extrae características de imágenes basadas en valores de píxeles y las combina con incrustaciones de texto creadas por un codificador de idioma. El modelo general encapsula las relaciones entre las incrustaciones de tokens de lenguaje natural y las características de imagen, como se muestra aquí:

El modelo de Microsoft Florence es simplemente un modelo de este tipo. Entrenado con grandes volúmenes de imágenes con subtítulos de Internet, incluye tanto un codificador de lenguaje como un codificador de imágenes. Florence es un ejemplo de un modelo fundacional . Es decir, un modelo general entrenado previamente en el que puede crear varios modelos de adaptables para tareas especializadas. Por ejemplo, puede usar Florencia como modelo de base para los modelos adaptables que realizan:
- clasificación de imágenes: identificación de la categoría a la que pertenece una imagen.
- detección de objetos: buscar objetos individuales dentro de una imagen.
- Captioning: Generar descripciones adecuadas de las imágenes.
- etiquetaje: Compilar una lista de etiquetas de texto relevantes para una imagen.
Los modelos multi modales como Florencia están en la vanguardia de la visión informática y la inteligencia artificial en general, y se espera que impulsen los avances en los tipos de soluciones que la inteligencia artificial hace posible.
Puntos clave
- Las imágenes digitales son datos numéricos.
- Los filtros permiten transformar imágenes y extraer características.
- El aprendizaje automático se usa para interpretar imágenes complejas.
- Las CNN son la arquitectura ideal para visión por computadora.
- Estas técnicas permiten tareas como clasificación, detección y segmentación.
Conclusión
La visión por computadora está revolucionando la forma en que las máquinas interactúan con el mundo. Desde simples filtros que detectan bordes hasta complejas redes neuronales que identifican rostros, el campo de Computer Vision está abriendo nuevas fronteras en la inteligencia artificial. Entender sus principios básicos es el primer paso para construir soluciones innovadoras y útiles en el mundo moderno.
Computer Vision es la puerta de entrada a que las máquinas entiendan el mundo visual. Desde reconocer un rostro hasta detectar enfermedades en una radiografía, esta disciplina combina matemática, programación y aprendizaje profundo para permitir una nueva era de automatización visual.
Saber cómo funcionan estos procesos te permitirá no solo comprender cómo “ven” las máquinas, sino también cómo diseñar sistemas más inteligentes y humanos.